HTML Introduction
HTML stands for HyperText Markup Language. At the most fundamental level, HTML is a language that creates structure and adds meaning for the content of a webpage.
A Language for Content
Different pieces of content play different roles and have different meaning. Think of an article in a magazine. There might be a title and various subheadings; there might be lists; and there would definitely be paragraphs. And we can identify this content by type. We could even label them:
HTML is a language all about content and its meaning.

That's basically what HTML does: It marks-up (that's the "M" in "HTML") content to assign it a type or role. In fact, we can use HTML to indicate the same meanings as we did above with labels:

By writing content marked up with HTML to assign correct roles, we create a document with structure and meaning for the browser to read and turn into a web page.
Elements
The basic unit of meaning in HTML is the element. An element is a piece of content and the specific meaning it carries, as well as the code used to mark it up.
The code that delineates an element is called tags. Many elements require two tags, an opening tag to indicate the start of an element and a closing tag to indicate its end:
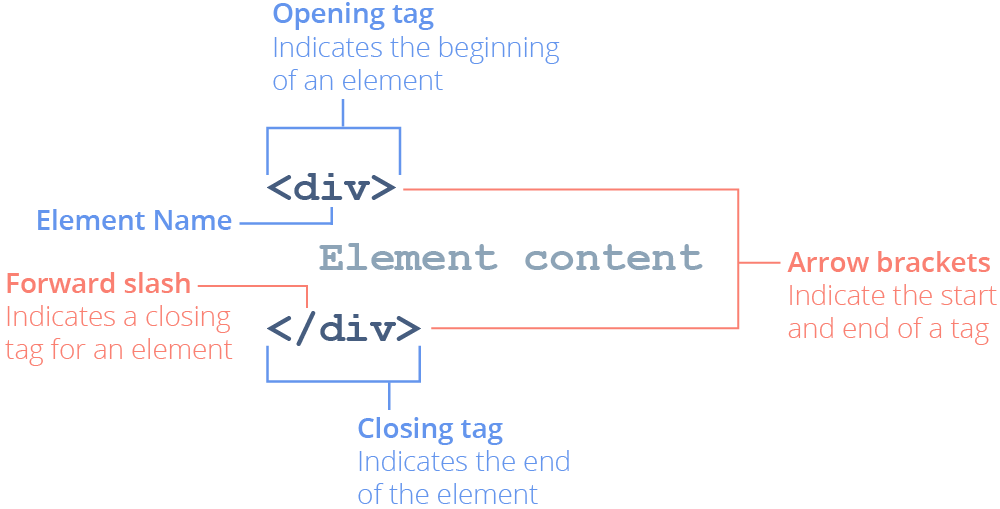
For instance, a paragraph element (<p>) needs opening and closing tags to enclose the text of the paragraph:
Nesting Elements
Often, elements enclose other elements to create a nested structure. We use the language of familial relationships to describe this. For instance, an element that encloses another would be called its parent, and the element that is inside the parent would be called a child. A simple example is the way an unordered list element (ul) serves as parent to list items (li):
Self-Closing Elements
There are some elements that don't need a closing tag because they don't wrap around any content. These elements are called self-closing elements. For instance, the <br> (break) element, which represents a meaningful line break:
Semantics
Each element in HTML has a very specifically defined meaning. Semantics is the practice of correctly using elements for content that matches their meanings.
The most important thing to know about HTML is that elements should be chosen based on their meaning.
Writing semantic code is essential for accessibility (making a site usable to people with alternative needs), search engine rankings, proper interaction with apps and extensions, and more.
Attributes
Sometimes you want to include a little more information about an element for the browser. Attributes are extra values attached to an element to add additional functionality or context. Some attributes are specific to certain elements, but others are more universal and can be used on any element.
Attributes are applied to an element by placing them inside the element's opening tag, after the element name but before the right angle-bracket:
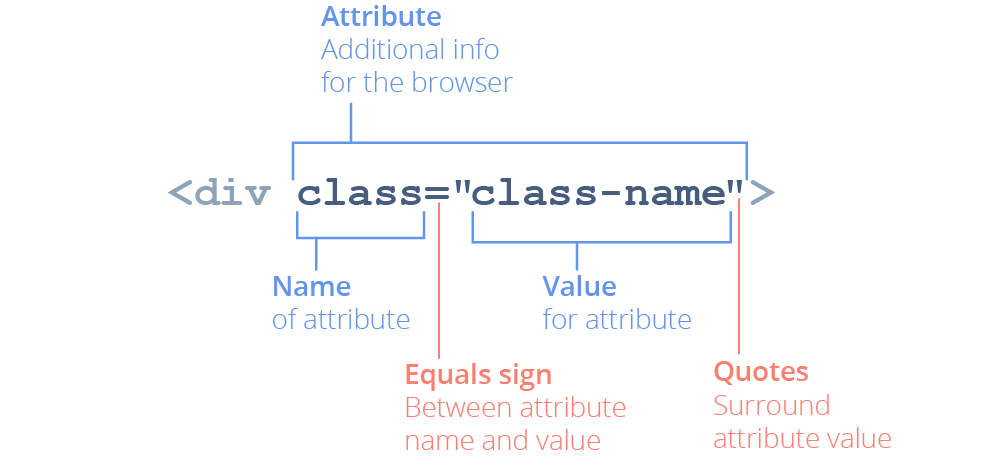
class attribute applies a name to a div element.On self-closing elements, attributes are simply placed inside the single tag:
src attribute identifies an image file to be used for the img element.Boolean Attributes
Many attributes have both a name and a value, but some need no value and need only be present to function. These are called boolean attributes:
required attribute needs no value and marks the form field as required by its presence.Multiple Attributes
You can place as many attributes as you need on a single element. Attributes in the same tag should be separated with a space:
input has three attributes: type, name, and disabled.There is no specific order in which attributes must be written, but a common approach is to put the most important attributes first.
HTML Files
HTML is typically written in .html files. An HTML file can have any name, so long as the .html file extension is present at the end. It is good practice to never use spaces or capital letters in file names on the web in order to avoid confusing browsers. In place of spaces, standard convention is to use dashes in what is amusingly referred to as "kebab-case" (get it?): about-our-company.html
The home page HTML file of a site should always be named index.html.
While an HTML file may have any name you like, it's important that the home page for a website be named index.html. This is because a browser looking at a domain name or a directory (folder) automatically looks for a file named index.html to display. If there is no file with that name, browsers simply list the files and directories present.
There is certain code, commonly referred to as skeleton code, that is necessary in every HTML document. To learn more, see the skeleton code chapter.